
Regression analysis is used to model the relationship between a response variable and one or more predictor variables. STATGRAPHICS Centurion provides a large number of procedures for fitting different types of regression models:

| Procedure | Statgraphics Centurion 18/19 | Statgraphics Sigma express |
Statgraphics stratus |
Statgraphics Web Services |
StatBeans |
|---|---|---|---|---|---|
| Simple Regression |  |
|
|
|
|
| Box-Cox Transformations | |
|
|||
| Polynomial Regression | |
|
|||
| Calibration Models | |
||||
| Multiple Regression | |
|
|
|
|
| Comparison of Regression Lines | |
||||
| Regression Model Selection | |
||||
| Ridge Regression | |
||||
| Nonlinear Regression | |
|
|||
| Partial Least Squares | |
||||
| General Linear Models | |
||||
| Life Data Regression | |
||||
| Regression Analysis for Proportions | |
||||
| Regression Analysis for Counts | |
||||
| Orthogonal Regression | |
||||
| Classification and Regression Trees | |
||||
| Piecewise Linear Regression (V19 only) | |
||||
| Quantile Regression (V19 only) | |
||||
|
Stability Studies (V19 only) |
|
||||
| Zero-Inflated Count Regression (V19 only) | |
The simplest regression models involve a single response variable Y and a single predictor variable X. STATGRAPHICS will fit a variety of functional forms, listing the models in decreasing order of R-squared. If outliers are suspected, resistant methods can be used to fit the models instead of least squares.
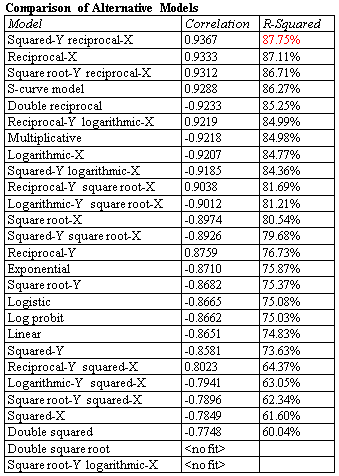

More: Simple Regression.pdf
When the response variable does not follow a normal distribution, it is sometimes possible to use the methods of Box and Cox to find a transformation that improves the fit. Their transformations are based on powers of Y. STATGRAPHICS will automatically determine the optimal power and fit an appropriate model.

More:Box-Cox Transformations.pdf

Another approach to fitting a nonlinear equation is to consider polynomial functions of X. For interpolative purposes, polynomials have the attractive property of being able to approximate many kinds of functions.

More: Polynomial Regression.pdf
In a typical calibration problem, a number of known samples are measured and an equation is fit relating the measurements to the reference values. The fitted equation is then used to predict the value of an unknown sample by generating an inverse prediction (predicting X from Y) after measuring the sample.

More: Calibration Models.pdf
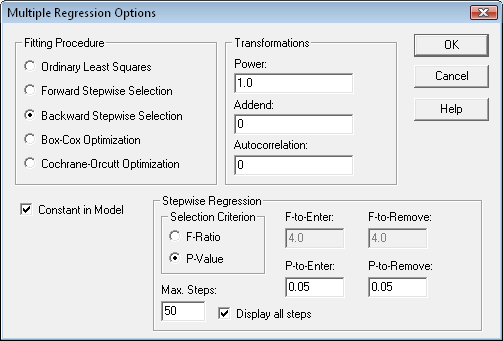
The Multiple Regression procedure fits a model relating a response variable Y to multiple predictor variables X1, X2, ... . The user may include all predictor variables in the fit or ask the program to use a stepwise regression to select a subset containing only significant predictors. At the same time, the Box-Cox method can be used to deal with non-normality and the Cochrane-Orcutt procedure to deal with autocorrelated residuals.
In some situations, it is necessary to compare several regression lines. STATGRAPHICS will fit parallel or non-parallel linear regressions for each level of a "BY" variable and perform statistical tests to determine whether the intercepts and/or slopes of the lines are significantly different.

More: Comparison of Regression Lines.pdf
If the number of predictors is not excessive, it is possible to fit regression models involving all combinations of 1 predictor, 2 predictors, 3 predictors, etc, and sort the models according to a goodness-of fit statistic. In STATGRAPHICS, the Regression Model Selection procedure implements such a scheme, selecting the models which give the best values of the adjusted R-Squared or of Mallows' Cp statistic.

When the predictor variables are highly correlated amongst themselves, the coefficients of the resulting least squares fit may be very imprecise. By allowing a small amount of bias in the estimates, more reasonable coefficients may often be obtained. Ridge regression is one method to address these issues. Often, small amounts of bias lead to dramatic reductions in the variance of the estimated model coefficients.

More:Ridge Regression.pdf
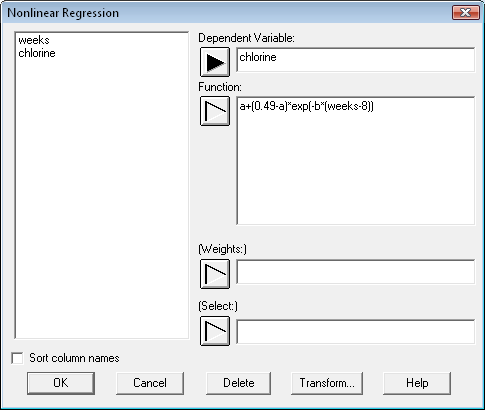
Most least squares regression programs are designed to fit models that are linear in the coefficients. When the analyst wishes to fit an intrinsically nonlinear model, a numerical procedure must be used. The STATGRAPHICS Nonlinear Least Squares procedure uses an algorithm due to Marquardt to fit any function entered by the user.
Partial Least Squares is designed to construct a statistical model relating multiple independent variables X to multiple dependent variables Y. The procedure is most helpful when there are many predictors and the primary goal of the analysis is prediction of the response variables. Unlike other regression procedures, estimates can be derived even in the case where the number of predictor variables outnumbers the observations. PLS is widely used by chemical engineers and chemometricians for spectrometric calibration.

More:Partial Least Squares.pdf
The GLM procedure is useful when the predictors include both quantitative and categorical factors. When fitting a regression model, it provides the ability to create surface and contour plots easily.

More:General Linear Models.pdf
To describe the impact of external variables on failure times, regression models may be fit. Unfortunately, standard least squares techniques do not work well for two reasons: the data are often censored, and the failure time distribution is rarely Gaussian. For this reason, STATGRAPHICS provides a special procedure that will fit life data regression models with censoring, assuming either an exponential, extreme value, logistic, loglogistic, lognormal, normal or Weibull distribution.

When the response variable is a proportion or a binary value (0 or 1), standard regression techniques must be modified. STATGRAPHICS provides two important procedures for this situation: Logistic Regression and Probit Analysis. Both methods yield a prediction equation that is constrained to lie between 0 and 1.

More:Logistic Regression.pdf,Probit Analysis.pdf
For response variables that are counts, STATGRAPHICS provides two procedures: a Poisson Regression and a Negative Binomial Regression. Each fits a loglinear model involving both quantitative and categorical predictors.

More:Poisson Regression.pdf,Negative Binomial Regression.pdf
Orthogonal Regression
The Orthogonal Regression procedure is designed to construct a statistical model describing the impact of a single quantitative factor X on a dependent variable Y, when both X and Y are observed with error. Any of 27 linear and nonlinear models may be fit.

More: Orthogonal Regression.pdf or watch video
Classification and Regression Trees
The Classification and Regression Trees procedure implements a machine-learning process to predict observations from data. It creates models of 2 forms:
The models are constructed by creating a tree, each node of which corresponds to a binary decision. Given a particular observation, one travels down the branches of the tree until a terminating leaf is found. Each leaf of the tree is associated with a predicted class or value.

More: Classification and Regression Trees.pdf
Piecewise Linear Regression (Version 19)
The Piecewise Linear Regression procedure is designed to fit a regression model where the relationship between the dependent variable Y and the independent variable X is a continuous function consisting of 2 or more linear segments. The function is estimated using nonlinear least squares. The user specifies the number of segments and initial estimates of the locations where the segments join.
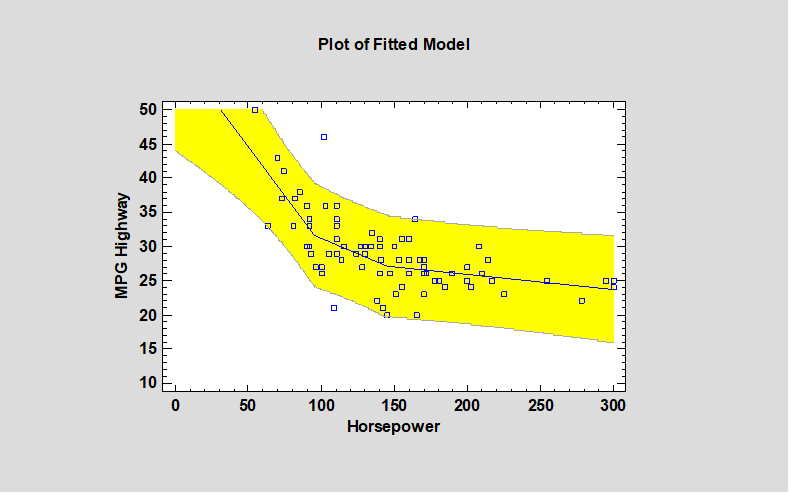 More: Piecewise Linear Regression.pdf or watch video
More: Piecewise Linear Regression.pdf or watch video
Quantile Regression (Version 19)
The Quantile Regression procedure fits linear models to describe the relationship between selected quantiles of a dependent variable Y and one or more independent variables. The independent variables may be either quantitative or categorical. Unlike standard multiple regression procedures in which the model is used to predict the mean response, quantile regression models may be used to predict any percentile. Median regression is a special case where the quantile to be predicted is the 50th percentile.
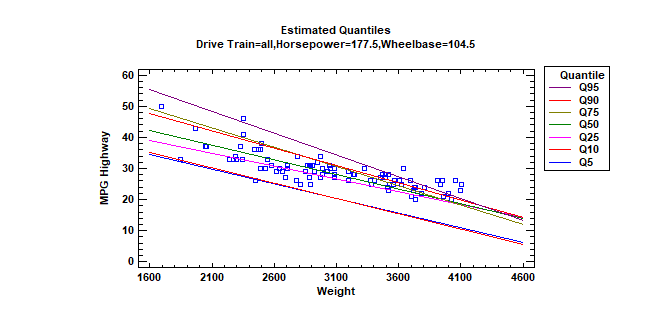 More: Quantile Regression.pdf
More: Quantile Regression.pdf
Stability Studies (Version 19)
Stability studies are commonly used by pharmaceutical companies to estimate the rate of drug degradation and to establish shelf life. Measurements are typically made on samples from multiple batches at different points in time. Of primary interest is estimating the time at which the lower prediction limit from the degradation model crosses the lower specification limits for the drug. Depending on the structure of the data, batches may be treated as either a fixed or random factor.
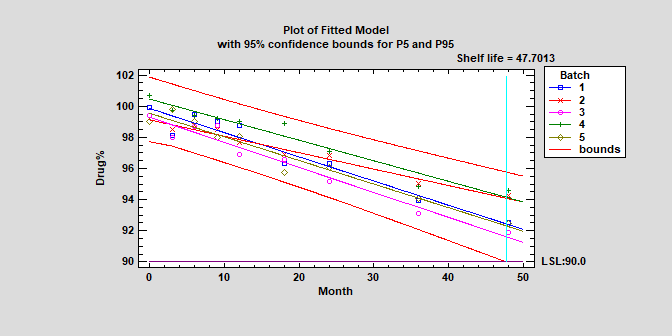
More: Stability Study.pdf or Watch Video
Zero-Inflated Count Regression (Version 19)
The Zero Inflated Count Regression procedure is designed to fit a regression model in which the dependent variable Y consists of counts. The fitted regression model relates Y to one or more predictor variables X, which may be either quantitative or categorical. It is similar to the procedures for Poisson Regression and Negative Binomial Regression except that it contains an additional component that represents the occurrence of more zeroes than would be expected in those models. Data containing excess zeroes is very common, including such diverse examples as the number of days a student is absent from school, the number of insurance claims within a population where not everyone has insurance, the number of defects in a manufactured item, and wild animal counts.
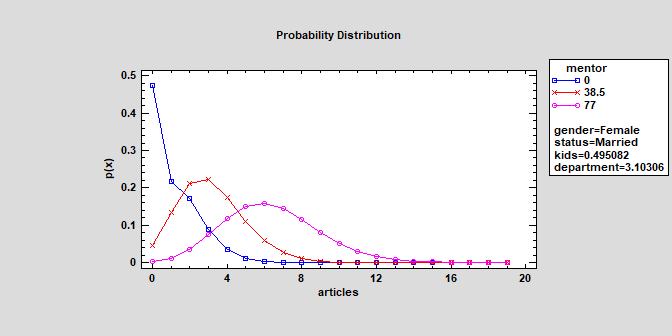
More: Zero-Inflated Count Regression.pdf or Watch Video


© 2025 Statgraphics Technologies, Inc.
The Plains, Virginia
CONTACT US
Have you purchased Statgraphics Centurion or Sigma Express and need to download your copy?
CLICK HERE


